ISPE recently hosted a webinar on Validation 4.0 and where it sat within their ISPE Pharma 4.0TM Operation Model. It was with no surprise that an audience survey rated ‘documentation’ as the biggest hurdle / constraint to validation.
Many people confuse documentation with validation, and are confused with the perceived expectation on the amount of documentation required to support a validated system or process.
The old statement ‘if it isn’t written down, then it didn’t happen’ gets drummed into our heads from QA.
It’s not that this statement is wrong. It’s just that this statement does not convey the level of documentation – or the format that this documentation has to take.
We mostly think of this documentation as paper records or electronic copies of these paper records (eg. Word or Excel).
With the current advancements in technology, it is time to challenge our approach to validation by using the actual technology that we plan to implement, and integrate this with the development and support methodology to enable a holistic control strategy.
Firstly, we need to look at the concept of a Digital Twin. A Digital Twin is a virtual representation of a physical object or process.
This can be created from as much real-time data that can be gathered from that physical object or process. The Digital Twin not only displays real-time data, but retains all the historical data and events to be able to be used as a future predictive modeler and potentially an auto-adaptive framework (using artificial intelligence and machine learning). This is possible as a Digital Twin provides a bidirectional information flow between the Digital and Physical Twins.
We can all imagine creating a Digital Twin from a physical object or process (which is the definition) but imagine creating a Digital Twin from a pseudo-physical object or process. A pseudo-physical object or process is what you describe when you are performing a process / computer validation exercise on a new process/system or change to an existing process/system.
Imagine you could develop this pseudo Digital Twin during the development process, and then ‘cut across’ the physical components as they became available. By integrating your pseudo and real Digital Twins you could seamlessly modify your operations with far less downtime than today.
Now imagine that as part of creating the pseudo Digital Twin, you implicitly capture all your baseline validation evidence; meaning only plans and reports need to be created around the outside of any change. This would be a game changer and greatly reduce the cost and time currently required to validate.
So, how can this happen?
The Virtual Process Layer
During the ISPE Validation 4.0 webinar, they suggested replacing the detailed requirements with swim lane process maps together with data maps.
Most of us would be familiar with the swim lane concept and probably use it as the static beginning to our current requirements gathering exercise anyway (see Figure 1).
Figure 1 – Example swim lane diagram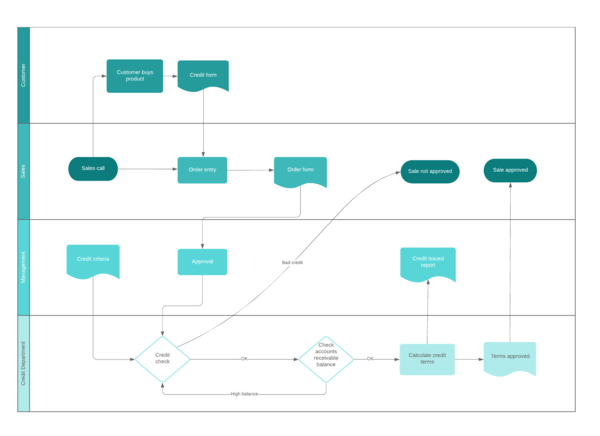 The problem is that it is currently just that – a static representation of a process.
The problem is that it is currently just that – a static representation of a process.
If we can develop this as a dynamic model (either initially gathered by using a process mining tool on an existing process or manually created but eventually overlaying on the Digital Twin), then we have a powerful tool that can be used by the business to maintain and optimise the process.
Although the diagram shows a process in an easy to understand visual way, the ability to be able to drill down and across to related processes is also required.
Although the diagram also implies some rules, it doesn’t allow the space to record these rules.
The Virtual Rules / Requirements Layer
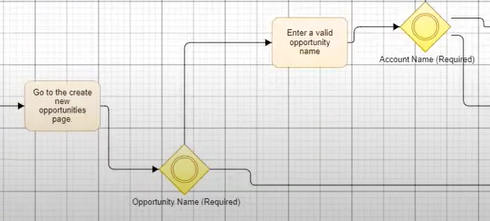
By allowing rules (which are really just the requirements within a standard User / Functional Requirements Specification) to be added per process bubble, the baseline requirements level evidence can be captured and retained.
Many of these requirements either implicitly or explicitly refer to data – both input and output.
Figure 2 – Addition of Rules and Data Layer
Risk Assessment
A GAMP functional risk assessment can be performed on each test case, setting the framework for the testing strategy.
Using a Computer Software Assurance (CSA) validation approach, these functional tests and risks will put a weighting on the testing paths as they are combined with the design and development knowledge.
The Virtual Data Layer
This is where the framework gets interesting. The Virtual Data layer starts as a set of named points (eg. name, address, temperature, etc), maps into a set of ‘dummy’ fields that can contain pseudo data for testing, and finally maps into real data from actual systems or equipment.
This ability to evolve and consist of a combination of data in the different states allows the overall pseudo Digital Twin and Digital Twin to co-exist.
Vendor Collaboration
As a short aside, another ISPE Pharma 4.0 working group (the Plug and Produce SIG) is proposing an Open Platform layer using OPC UA (Open Platform Communications Unified Architecture) that would allow any system or device to talk with another device through a common standard.
As many vendors / devices have greatly differing communication protocols, the group is suggesting developing a standard, and then relying on individual vendors to create a common interface to their device / equipment over their current proprietary protocols.
This is a neat approach as it provides a self-governing framework for future development.
The Virtual System / Equipment / Device Layer
Along the same line, if software and equipment vendors were to provide a starting Virtual Process Layer / Virtual Rules Layer / Virtual Data Layer and Design Layer (see below), or subsets of these that were relevant to the configurability of their solution, these could be integrated into a specific company’s pseudo Digital Twin.
Note that in many instances, you may not know who the vendor is when starting the process, so the ability to be able to ‘plug and produce’ a vendor’s different layers into an existing partial pseudo Digital Twin would be beneficial.
Analogous to the OPC UA concept, if a similar standard was applied to calls between systems (eg. ‘Create Deviation’ would initialise a deviation in whatever system was connected at the time), and vendors were able to provide a starting set of virtual layers, companies could create entire process environments without the need for the actual systems or devices.
The Design Layer
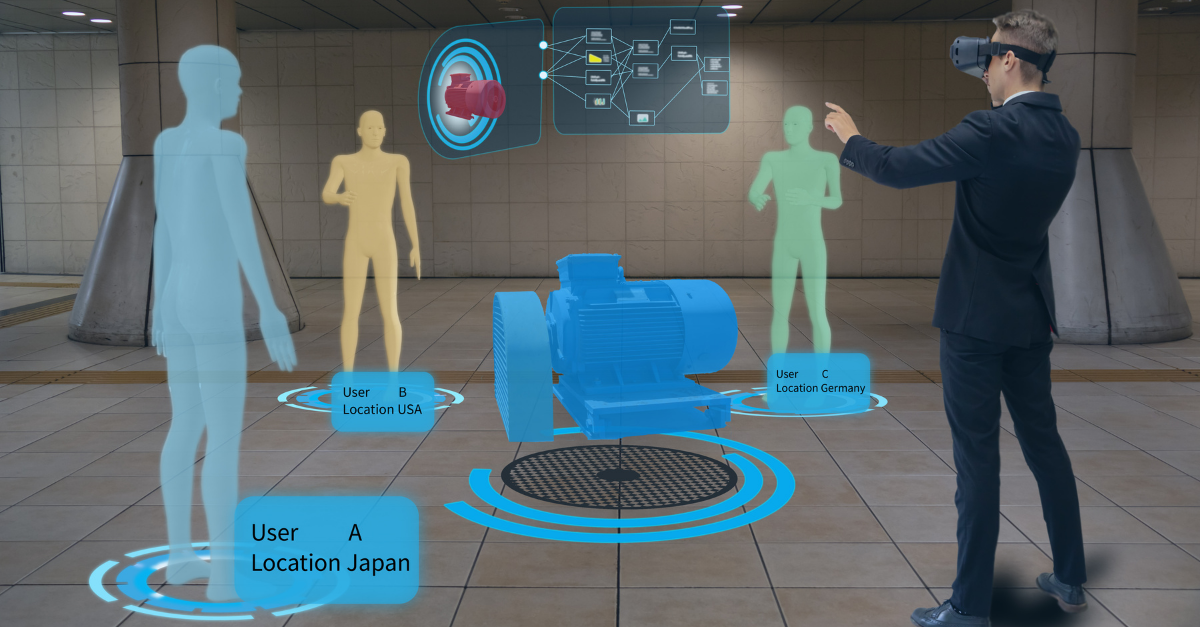
It would also be beneficial that if when a vendor provided their design layer to the model, a representation of the User Interface to the system or device was available for visualisation and prototyping of the process.
A level of Virtual Reality (VR) could be overlayed to provide end users with a powerful tool for further requirements inspection and review. This could be performed at any time, but becomes more informative as more and more design level information is added.
As the design layer is created, the functional requirements / test cases can be mapped / combined with the relevant areas in the design.
As mentioned above, by using risk assessment and critical thinking under a CSA validation approach, each test is risk assessed as a combination of its functional risk rating and its design implementation approach (out of the box, configured or customised). This will set the focus for the testing approach based on both the knowledge of the process and how the solution is to be developed / implemented.
Design Level Verification
At this stage, the Virtual Data Layer contains a set of ‘dummy’ fields where data can be stored and used (either through the representation of the UI or through a VR simulation).
Obviously, ‘real’ data is optimal, so as soon as real data becomes available (requires a connection to a physical entity) then it should be integrated into the model.
But even with ‘dummy’ fields, the model allows for a pseudo run though of the entire process without having any software or hardware available. This approach can also allow for a better comparison of vendors’ solutions in a company’s real life situation prior to actually purchasing the product / device.
It also assists with the expansion and refinement of requirements.
The better ‘data simulator’ that a vendor can provide, the better this process simulation will be.
Auto Test Generator
Even before the system / process is developed, if the Virtual Process Layer, the Virtual Rules / Requirements Layer and the Design Layer are accurate, tools exist to auto create test cases through all paths. With the extra benefit of having a risk framework over the process paths, extra testing and specific test evidence capture can be used to refine and focus the testing strategy.
These test cases can be exported and imported into a test execution tool that can be performed on the physical system at a later time.
Auto Test Data Generator
By setting up a series of calls that can retrieve test data in both the Digital Twin and Physical Twin, these can be overlayed in the models and used during automatic testing.
Examples of this could be ‘Get QA User’, ‘Get Batch in Quarantine Status’ etc. Database calls under these would run and return valid data matching that criteria at that time.
Vendors who supplied this layer as part of their solution to customers would be at a distinct advantage. Alternatively, developers could develop and maintain these as part of system development.
Moving from the pseudo Digital Twin to the real Digital Twin
As the physical system or equipment is developed or provided, both the Virtual Data Layer and Virtual System / Equipment / Device Layer can be updated with the Physical Twin.
Testing the Physical System
A level of testing can occur even before a system is developed, but when the system is developed, the output from the test and data generators can be imported into an automated test runner tool and a full set of tests can be performed.
Similarly, as part of a test plan developed from the full set of tests, a subset of tests could be developed to focus on specific elements and transferred to the test runner tool.
Some level of human involvement can be built into the automatic testing as required (eg. screen layout inspection, manual parameter input) but predominantly the testing can be automated to test the functional requirements.
Validation Documentation
So, to get back to question of validation.
The framework itself and the tools used would need some level of validation to demonstrate that they worked reliably and consistently.
But for each process and system, the solution and validation documentation would be contained within the pseudo Digital Twin, which would overlay the Digital Twin when the Physical Twin came into existence.
Configuration management and change management would be critical in maintaining the structure, but no more than is required in the current approaches.
Conclusion
The benefits of the Digital Twin are many, and the real benefits will be realised when a company has a completely integrated digital environment.
Being able to perform both predictive and adaptive actions based on a real-time picture of the environment and by using historical data with data / process intelligence is where all companies will want to be in the near future.
The questions is – why just limit this after systems are operational.
As with the old ‘chicken or the egg’ conundrum, by utilising modern technology and a CSA approach to validation, the dreaded ‘documentation’ fear may be a thing of the past – in a near future state.
You may also be interested in this related content:
- Training
- Blog Series: Quality Management under MTP 4.0